|

| | Нагрузки и производительность |
Системная платформа должна уметь работать эффективно с большими объемами данных и при большом количестве одновременно работающих пользователей. Платформа STOR-M спроектирована и реализована таким образом, что позволяет поддерживать высокую и предказуемую производительность системы при ОЧЕНЬ больших нагрузках. Для демонстрации таких возможностей было проведено нагрузочное тестирование платформы STOR-M, условия и результаты которого приведены ниже.
Тестовые условия | Конфигурация программной части | Количество созданных в архивной системе пользователей: 5000
Из них одновременно подключенных и выполняющих активные действия в системе: 1000
Выполняемые действия: просмотр структур и каталогов, открытие карточек, выполнение поисковых запросов и открытие карточек из результатов.
| - ОС Red Hat Enterprise Linux 5.2 64 бит, “из коробки”.
- СУБД MySQL 5.0.67 64 бит , сконфигурированная с механизмом INNODB и выделенным объемом памяти 8 ГБ.
- Физические файлы БД и файлы с логами транзакций разнесены по отдельным RAID массивам.
- Платформа STOR-M, установленная и сконфигурированная на использование 6 ГБ
оперативной памяти для сервера приложений.
Все части системы (СУБД и сервер приложений) расположены на одном физическом сервере.
|
Описание тестового плана | Тестовая нагрузка имитировалась путем запуска программного имитатора клиентских приложений, использующего тот же API что и настоящее клиентское приложение STOR-M и выполняющего идентичный набор вызываемых с сервера функций. На этапе подключения, программный имитатор последовательно, с интервалом в одну секунду, выполнял подключение к системе пользователей. Затем, после того, как все пользователи были подключены, программный имитатор запускал 1000 потоков, каждый из которых имитировал типичные действия пользователя в системе, непрерывно, в течении 1 часа. Все действия сохранялись в текстовый файл для последующего статистического анализа.
Каждый из 1000 потоков выполнял по циклу (до окончания отведенного времени тестирования в 1 час) следующие действия:
случайным образом выбирал стартовый каталог в электронном архиве, по которому начинал рекурсивный обход до глубины в 20 уровней. На каждом из уровней, открывались на просмотр все найденные там карточки. Далее, на текущем уровне случайным образом выбиралась папка для углубления, после чего процесс повторялся. Рекурсивный обход заканчивался по достижению глубины в 20 уровней или по окончанию вложенных элементов. Случайным образом выбирался механизм поиска - полнотекстовый или атрибутивный, после чего, из соответствующего словаря в 1000 вариантов, случайным образом выбирался поисковый запрос, который исполнялся на сервере. Из полученного в результате поиска списка карточек, система открывала случайно выбранные 20 штук.
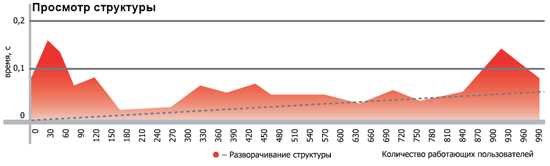
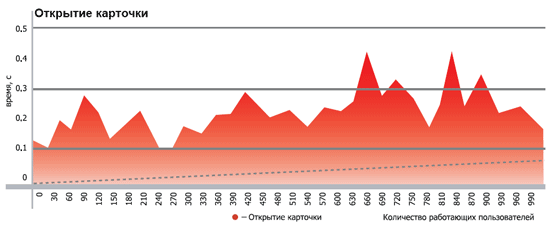
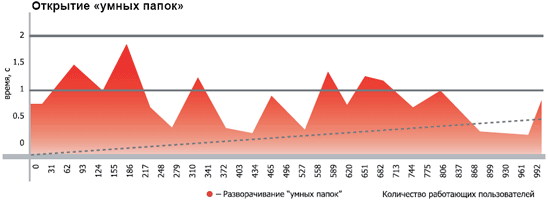
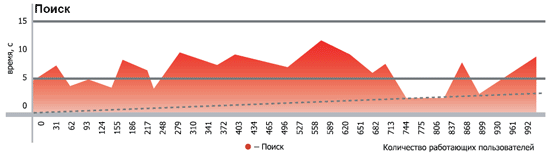
| Первичные наблюдения | В процессе проведения тестирования было выявлено, что до 100 активных пользователей практически не влияют на быстродействие системы - среднее время ответов на запросы составляло от 6 до 20 мс. Начиная со 101 пользователя, времена ответов сервера начинали плавно повышаться до 200-300 мс. В конечном итоге, среднее время ответа сервера на 1000 активных пользователях стабилизировалось в райное 400-1000 мс. Исключение составляли периодические пиковые скачки до 3 ... 6 сек, когда сервер приложений запускал процедуру сборки мусора, при обнаружении активного использования оперативной памяти и срабатывании критерия активации процедуры сборки мусора. Средняя продолжительность выполнения такой процедуры составляла от 3 до 10 секунд.
| Расход памяти | Выделенные серверу приложений 6 ГБ оперативной памяти на подключение пользователей расходовались незначительно, не более 300 МБ в общей сложности на 1000 подключенных клиентов. Однако, в процессе активной работы пользователей, расход памяти достигал значений в 3-4 ГБ. В основном, память расходовалась для получения от СУБД, обработки и отправки клиенту объектов, полученных в результате поиска или иных запросов. В последствии, при срабатывании алгоритма сборки мусора, ранее занятая память освобождалась для новых запросов. Подводя итог, можно сказать, что для озвученных в настоящем тесте условий в 1000 одновременных пользователей, выделение 6 ГБ оперативной памяти на сервер приложений является достаточным для стабильной работы. Однако, для большей оптимизации быстродействия, можно
рекомендовать использовать значение в 8 ГБ совместно с включением кеша второго уровня в сервере приложений (настоящее тестирование проводилось с выключенным кешем) - это позволит кешировать в памяти наиболее часто востребованные пользователями запросы и кардинально снизить нагрузку на СУБД и время ответа системы в целом. Впрочем, это не является необходимым условием для поддержания оптимальной производительности на описанных в настоящем документе условиях.
| Нагрузка на процессор | В среднем, за время активной работы 1000 пользователей, было использовано от 1/2 до 3/4 мощностей процессорв/ядер. Постоянной пиковой загрузки в 4/4 (400%) не наблюдалось.
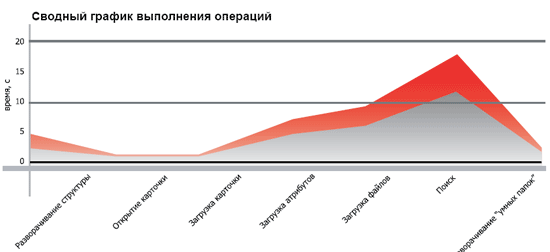
| Результаты тестирования | Ниже представлены графики производительности, где в наглядном виде показаны средние скорости ответа и обработки основных запросов к системе. Замер времени производился от момента формирования запоса до появления первых данных в интерфейсах платформы STOR-M.
|
|
|
|